|
||||
| [ NORM v. 1.1 | original version ] | The Vowel Normalization and Plotting Suite | |||
|
| ||||
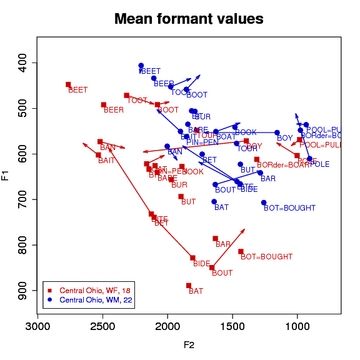
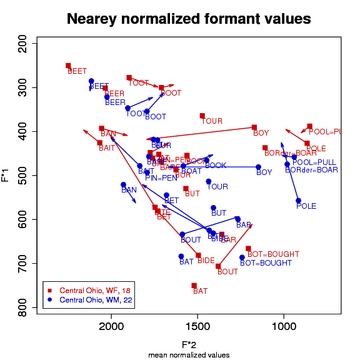
About Vowel NormalizationVowel normalization techniques have been developed because different speakers have different mouth sizes, which in turn causes their formant resonances to differ. Vowel normalization is crucial in order to compare the vowel realizations by different speakers in meaningful linguistic and sociolinguistic ways. Compare, for example, Figures 1 and 2; in Figure 1, the male speaker's formant values are much lower and more compact than for the female speaker. Yet, they come from nearby towns and speak similar dialects. How much of that difference is actually socially and sociolinguistically meaningful and how much is simply physiological? Normalization is necessary in order to answer such questions.
There are a few issues of which you should have some awareness before you decide whether vowel normalization is right for your project. First, and most important, is what the purpose of normalization is. Disner (1980) and Thomas (2002) list four general goals:
Most phoneticians who work with vowel normalization focus on goal #4. For example, the extensive review of normalization in Rosner and Pickering (1994) takes goal #4 as THE purpose of normalization, without even entertaining the notion that there could be any other use for normalization. To complicate matters, some researchers have recently suggested that listeners do not actually normalize vowels at all, and that comprehension of the vowels of different speakers operates by other means (Pisoni 1997). However, the majority opinion is still that listeners do normalize, and Rosner and Pickering (1994) conclude that F1 and F2 are by far most important, with F3 occasionally important and F0, in spite of suggestions by numerous researchers, not important at all. In addition, a few researchers have suggested that dynamic portions of vowels, i.e., where formant values are changing, may be more important than steady-state vowels (e.g., Nearey and Assmann 1986; Strange 1989). This issue relates to a larger goal of phoneticians, the quest for invariance. Invariance is the notion that a given speech sound has some properties that would be invariant if one could just find the right phonetic properties or the right transformation of phonetic properties. For sociolinguists and dialectologists, however, goal #4 is the least important of the four. Our traditional concern has been to discern the relationship between language and society. If we can speak to goal #4, so much the better, but it is dispensable for most sociolinguistic studies. Goal #3, preserving phonological contrasts, is most often not a concern, either. In a language such as Spanish, for which vowels lack length or tenseness distinctions and for which the diphthongs are not phonemic, we would expect vowel normalization to meet goal #3. However, in languages such as English, Dutch, German, and Swedish, many vowel contrasts are effected by factors other than steady-state formant values, so we shouldn't expect vowel normalization to meet goal #3. For sociolinguists and dialectologists, it is the first two goals that matter. For us, an effective vowel normalization technique is one that filters out physiological differences (goal #1) but leaves sociolinguistic differences unaffected (goal #2). Hence, a normalization technique that phoneticians might reject could serve our needs perfectly well. The criteria sociolinguists use for evaluating a normalization technique, then, should differ from those used by phoneticians. A second consideration is that vowel normalization techniques fall into two general groups: vowel-intrinsic and vowel-extrinsic. In a vowel-intrinsic method, all the information used for the normalization formula can be found within a single vowel token. These methods use various combinations of formant values (F1, F2, usually F3, and occasionally F4), F0 (the fundamental frequency), or even formant bandwidths. Vowel-extrinsic methods, on the other hand, compare formant values of different vowels spoken by a given individual. An analogous distinction is between speaker-intrinsic and speaker-extrinsic methods. Speaker-intrinsic methods normalize based on data from a single speaker's vowels. Speaker-extrinsic methods, such as the one used by Labov, Ash, and Boberg (2006), factor more than one speaker's vowels into the formula (in fact, Labov et al. stated that their grand mean - which was computed from all the speakers in a sample - continued to change until 345 speakers were used!). Another consideration is whether to scale the normalized values or not. Most normalization formulas yield numbers that don't resemble the Hertz values from which they were derived, and many people find it hard to visualize how those numbers relate to vowel quality. Scaling is an attempt to solve that problem. It involves converting any speaker's normalized formant values to a scale, such as 250 to 750 Hz for F1, that corresponds to a range of Hz values found in unnormalized vowels. (See the section on About Scaling for how NORM scales normalization results.) Four useful reviews of normalization techniques are Hindle (1978), Disner (1980), Miller (1989), and Adank, Smits, and van Hout (2004). They put varying weights on the four goals stated above. Hindle (1978) preferred vowel-extrinsic methods, particularly a now widely-used formula developed by Nearey (1977). Disner (1980) discussed goal #2 at length, noting that different languages appear to use the periphery of the vowel envelope in different ways, and found that vowel-extrinsic methods were not especially effective at capturing such differences, even though they performed well in other ways. Miller (1989) provided some useful history on vowel-intrinsic methods. Finally, Adank et al. (2004) evaluated how well different formulas matched impressionistic transcriptions and came down solidly in favor of vowel-extrinsic methods, especially those by Lobanov (1971) and Nearey (1977). However, their experiment had essentially stacked the deck, since, of the supposed "vowel-intrinsic" methods they tested, only one--that of Syrdal and Gopal (1987)--was really a vowel normalization technique. The others, such as conversion of Hz to Bark or mels, were simply transformations of Hz to scales that reflect auditory treatment of pitch. | ||||
| NORM v. 1.1 Last Mod: 11/18/2015 | © Erik R. Thomas & Tyler Kendall 2007-2015 erthomas [at] ncsu.edu & tsk [at] uoregon.edu |