|
|||||||||||||||
| [ New NORM v. 1.1 | original version (v. 0.9) ] | The Vowel Normalization and Plotting Suite | ||||||||||||||
|
THIS IS THE OLD VERSION OF NORM. UNLESS YOU ARE HERE FOR A REASON, YOU SHOULD USE CURRENT VERSION.
| |||||||||||||||
Using NORMUsing NORM to normalize your sociophonetic vowel data is relatively straightforward. In order to use NORM, you'll need to have your speakers' raw vowel data in a spreadsheet in the format described in the preparing your data section (below). You can also use our templates or view our sample files to help format your data. Once your vowel data are in the right format, you can simply to use the main NORM form to upload your file and select the method(s) to process your vowel data and plot the results. For information about how NORM works and for information about vowel normalization in general and the specifics of the various methods, see the About NORM page. Preparing Your DataIn order for NORM to process your data, they must be in tab-delimited text files. The files should start with one row that contains header information (e.g., "speaker","vowel", "context", "F1", "F2", ...). The specific text of the header row is entirely up to you, provided that the columns are in the following order:
Each row in your file should contain the data for one vowel instance. Your spreadsheet should contain measurements for individual vowel tokens, not mean values.
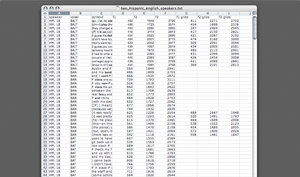
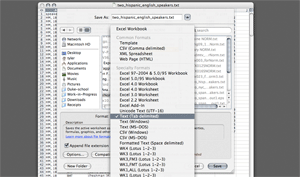
The easiest way to make a tab-delimited text file is to build the file as a spreadsheet in MSExcel or OpenOffice.org. When you've entered (or copy/pasted) all of your data into the file you can simply save the document as a Text (Tab delimited) file. A sample file is illustrated by the screenshot in Figure 1 and available for download (below); Figure 2 shows the "Save As..." window in MS Excel (on a Macintosh). We recommend you download one of our templates to use. You're also welcome to download a sample file, which you may find illustrative to look at or to test NORM with. Please note, NORM only supports files with ASCII or simple UTF-8 character encodings. Praat, MS Excel, and other software will let you create files with richer character sets (such as IPA characters or other UTF-16 encoding characters). These will not work through NORM's web interface however, so you will need to ensure that you use simple characters (like the arpabet system or Wells keywords) to label your data. See Tyler's post on plotting with IPA in Vowels.R for a work around using the Vowels.R package. Download: (you may need to right-click and select "Save File As...")
| |||||||||||||||
| NORM Last Mod: 11/18/2015 | © Erik R. Thomas & Tyler Kendall 2007-2015 erthomas [at] ncsu.edu & tsk [at] uoregon.edu |